Sprout
A privacy-first AI desktop application for care-experienced young people to navigate their own social care records
Problem
Young people who have been through the care system are legally entitled to access their own social care records. In practice, those records are dense, bureaucratic documents — written in professional shorthand, full of third-party assessments, often containing deeply distressing content about the person’s own history.
A young person would receive a folder of documents with no context, no guidance, and no way to navigate them. For users with trauma histories and low institutional trust, this wasn’t just a UX problem — it was a safeguarding one.
Therewith’s mission was to change that: AI designed with, for, and by care-experienced young people — to help them make sense of their own stories, understand their rights in plain language, and surface the positives buried in crisis-focused records. With one hard constraint: no data could leave the device. Privacy wasn’t a feature — it was the foundation.
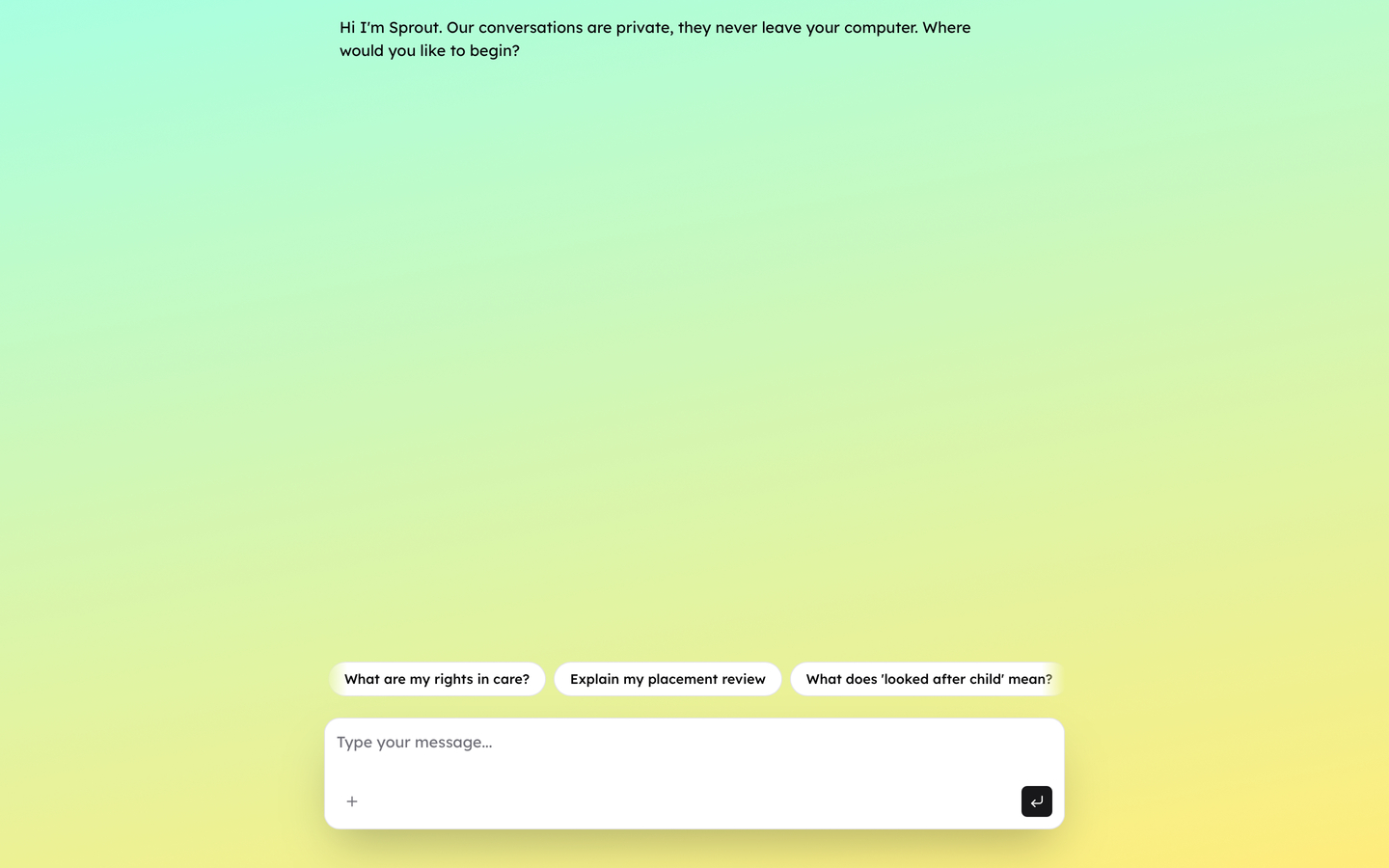
Interaction model
The empty state includes conversation starters drawn from Therewith’s sessions with care-experienced young people — explaining Sprout’s focus and surfacing the most common questions instantly.
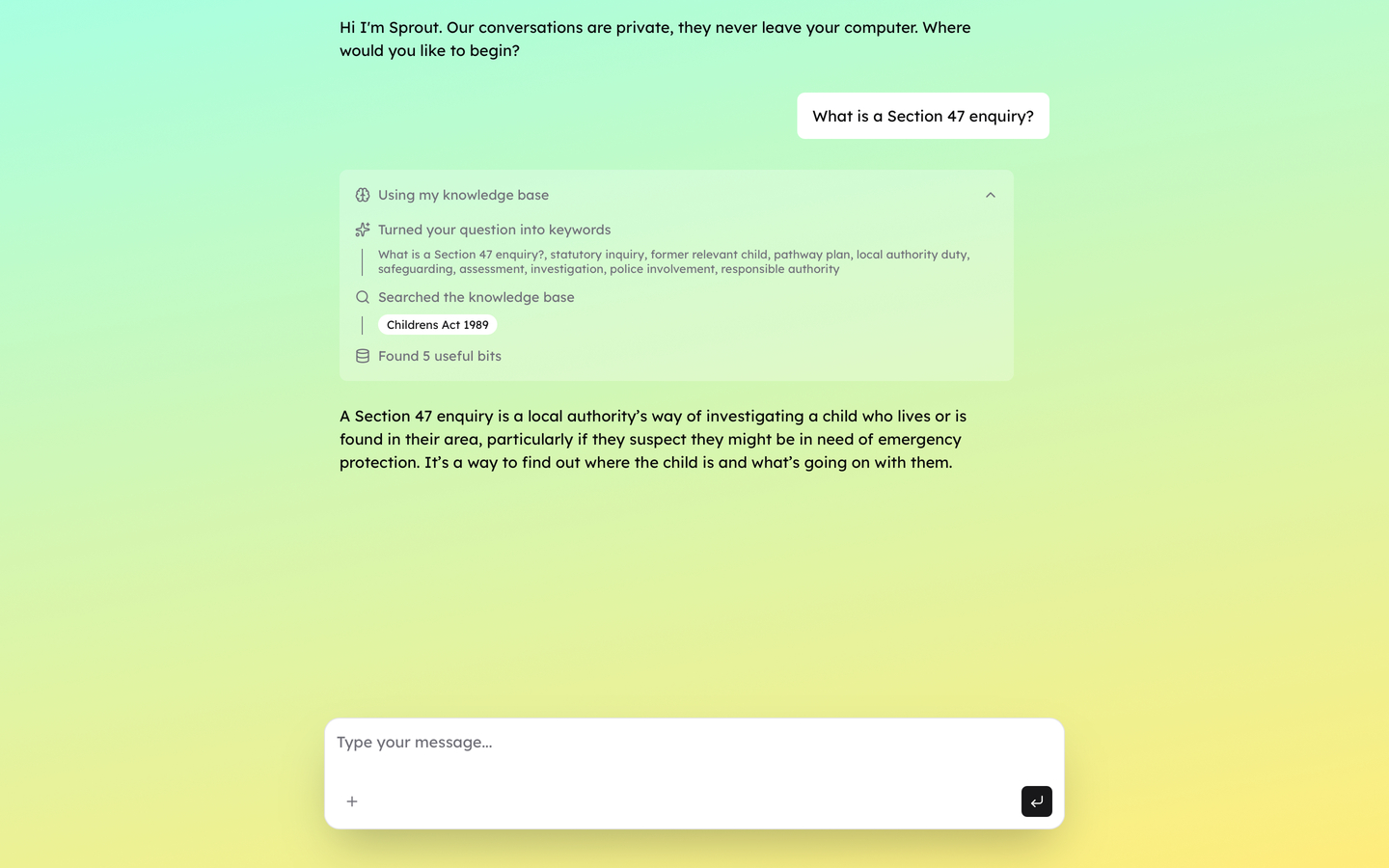
The AI needed to answer questions beyond the user’s own records — about rights, legal entitlements, and official processes. I built a RAG pipeline that ingested key UK government documents and stored them as a SQLite file. Every new chat session seeds an in-memory database from this file, giving the AI a stable knowledge base to quote official language or clarify entitlements accurately. I then built a custom retrieval process that combined semantic and full-text search to ensure the more accurate results are used.
Trust required transparency. I designed a chain-of-thought UI component — using age-appropriate language — that surfaces how the AI generated each response: whether it drew from the user’s records, the knowledge base, or both, and most importantly how it converts the users language in to search keywords.
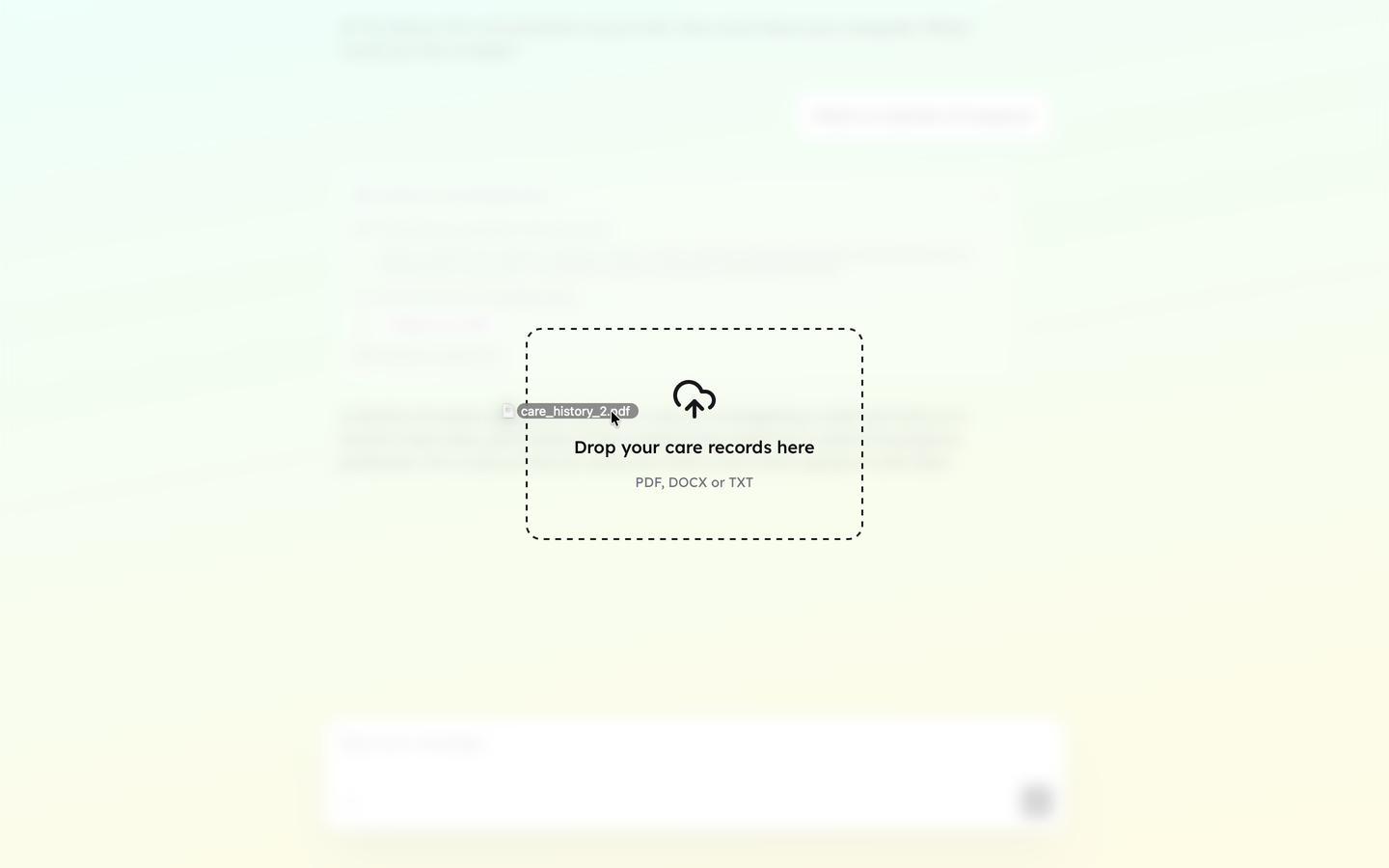
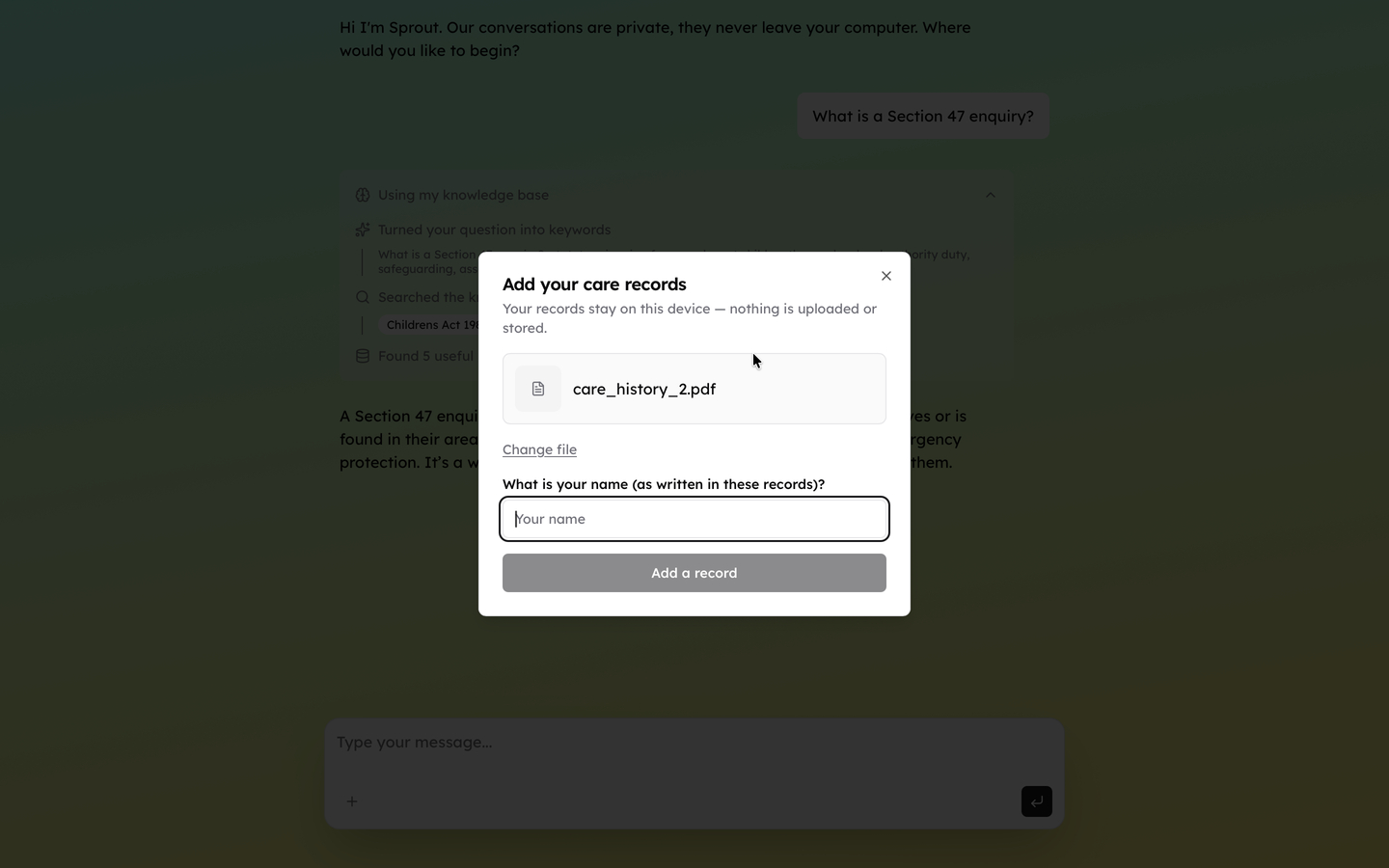
Users needed to add their documents without friction. I built a processor for .txt, .docx, and PDF files that breaks each document into chunks, summarises each chunk, then stores the original, summary, and vector embedding in the same database as the official documents. A 90-page PDF takes 3–4 minutes end to end – processed entirely on the users device. Users drag files over the window or tap ”+” then a progress bar narrates each step in plain language. Once processing completes, a summary explains in plain terms what the AI now understands from that document.
Getting the tone right required sustained prompt engineering work. I spent significant time revising prompts to work with the model’s natural tendencies rather than against them. One example: the model consistently used a person’s name when reading from their records rather than “you” or “your”. Rather than suppress this, I adjusted the framing to “here’s what your document says to me…” — making the third-person prose feel considered rather than cold.
Truthfulness was equally critical. The AI could not fabricate data, make assumptions, or guess a key fact. When it lacked enough information it asked a clarifying question; when a question fell outside its knowledge base it said so directly — “the answer to your question is outside my knowledge base, would you like suggestions on who to ask?” — and offered a path forward. No dead ends. If the AI doesn’t know, it says so.

Technical architecture
Fully local inference — no cloud API calls, no data transmission — ruled out every typical AI product pattern. The model had to run on consumer laptops without GPUs.
- Stack: Tauri + React + Bun (desktop shell + RAG Toolkit)
- Model: gemma3:1b-it-qat — CPU-only with acceptable latency on low-resource hardware
- Embeddings: nomic-embed-text — strong semantic retrieval at low resource cost
- Observability: Langfuse running locally — full tracing of every inference call, retrieval result, and evaluation outcome, nothing leaving the device
- Database: A new in-memory SQLite database is created, seeded with relevant knowledge, and deleted for each session — no user data persists
- Accessibility: Fully accessible UI and design system built on shadcn — keyboard navigable throughout
The RAG pipeline was custom-built because the document structure of social care records is highly idiosyncratic. Headers, case worker identifiers, date structures, and section boundaries all required bespoke parsing before chunking.

The application needed to work on consumer laptops with no technical instruction. I chose Tauri + Bun because they produce small initial files (47MB for the entire Sprout .dmg) and a native install experience. The first time a user opens the app, both SLMs (Small Language Model) are automatically downloaded. They are only 1GB combined, and can be downloaded in a few seconds. Afterwards the application never sends or receives any other data.
Result
A production-ready desktop application with fully local inference on consumer hardware. A trauma-informed interaction model grounded in UCL research and co-designed with Therewith. An architecture where privacy is a structural guarantee, not a setting.